vLLM vs SGLang vs MAX — Who's the fastest?
Benchmarking Inference Engines and talking about metrics like TTFT, TPOT, and ITL.
LinkedIn is getting flooded with posts about AI Agent startups and the best coding models that promise to replace us coders are based on reasoning models like Deepseek-R1 or OpenAI’s o3. These developments mean even more inference, which puts computational pressure on AI infrastructure. Inference Engines—the powerhouses that keep the underlying LLMs running—are a core piece in the stack of AI production systems.
We will have a look and compare the current de facto standards, vLLM and SGLang, against a new contender, MAX.
Introduction
Large Language Models (LLMs) are incredibly demanding when it comes to computation, requiring significant hardware to perform inference—the process of turning inputs into outputs. Trying to run LLMs without an optimized inference engine can be a slow and inefficient ordeal. This is precisely why these engines are so crucial: they expertly manage resource usage, making the most of hardware like GPUs to slash memory and computational bottlenecks. They employ techniques to minimize the time it takes to generate responses, which is essential for real-time applications. Beyond that, they support the ability to handle many users or requests simultaneously through methods like batching, parallelism, and smart scheduling.
What’s more, inference engines enable advanced features such as quantization and attention optimizations, which not only boost performance but also help cut down on costs. They also simplify the whole deployment process by offering APIs and interfaces that make it easy to integrate LLMs into various applications and services. In short, these engines are indispensable for getting the most out of LLMs, making them practical, efficient, and scalable for a wide array of uses.
Setup
We are going to benchmark three inference engines:
- vLLM
- SGLang
- MAX
vLLM excels in throughput and memory efficiency, making it the default choice for many large-scale LLM deployments, with broad hardware and API support.
SGLang is tailored for high-performance, controllable inference with advanced scheduling, structured output, and multi-modal support, widely used in production pipelines.
MAX is a new, unified inference platform focused on hardware portability, developer productivity, and composability, leveraging modern compiler technology for speed and flexibility. It was recently released and is still not very well known. They showed promising results and claimed to be faster than vLLM.
So let’s find out.
The benchmark is going to be carried out on a cloud server:
OS: Ubuntu 22.04CPU: AMD EPYC 7763 64 coreGPU: NVIDIA L40 46GBDrivers: NVIDIA 550.90, CUDA 12.4For our benchmark, we chose Qwen/Qwen3-8B, a popular open-source model that serves as a good representative of a mid-sized language model, allowing us to evaluate performance on a commonly used scale.
For all three engines we are using the standard docker image that is provided by the respective engines on their official websites.
vLLM
docker run --runtime nvidia --gpus all \ -v ~/.cache/huggingface:/root/.cache/huggingface \ --env "HUGGING_FACE_HUB_TOKEN=${HF_TOKEN}" \ -p 8000:8000 \ --ipc=host \ vllm/vllm-openai:latest \ --model Qwen/Qwen3-8BSGLang
docker run --gpus all \ --shm-size 32g \ -p 8000:8000 \ -v ~/.cache/huggingface:/root/.cache/huggingface \ --env "HF_TOKEN=$HF_TOKEN" \ --ipc=host \ lmsysorg/sglang:latest \ python3 -m sglang.launch_server --model-path Qwen/Qwen3-8B --host 0.0.0.0MAX
docker run --rm --gpus=all --ipc=host -p 8000:8000 --env "HF_TOKEN=${HF_TOKEN}" --env "HF_HUB_ENABLE_HF_TRANSFER=1" -v $HOME/.cache/huggingface:/root/.cache/huggingface modular/max-nvidia-full:latest --model-path Qwen/Qwen3-8B --devices gpu:0 --max-num-steps 10 --max-batch-size 512MAX has noticeably the smallest docker image, then vLLM and last SGLang. This might be relevant for faster deployment which might be important when auto-scaling, and less storage in image caches.
Benchmark
We use the benchmark script benchmark_serving.py with the following options:
python benchmark_serving.py --base-url http://localhost:8000 --endpoint /v1/completions --backend {modular,vllm,sglang} --model Qwen/Qwen3-8B --dataset-path ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 500 --seed 123Prior to running the benchmark we warm up the three engines with a test run (same commands as above) to make sure that the caches are warmed up and the models are compiled.
Surprising Results
First, let’s see how long each engine takes to complete all 500 prompts.
MAX completes all 500 prompts in roughly 50.6 seconds, SGLang in 54.2 seconds while vLLM takes 58.9 seconds. This makes vLLM 8 seconds slower, around 16% slower than MAX.
LLM inference can be split into two phases with different compute characteristics: prefill and decoding.
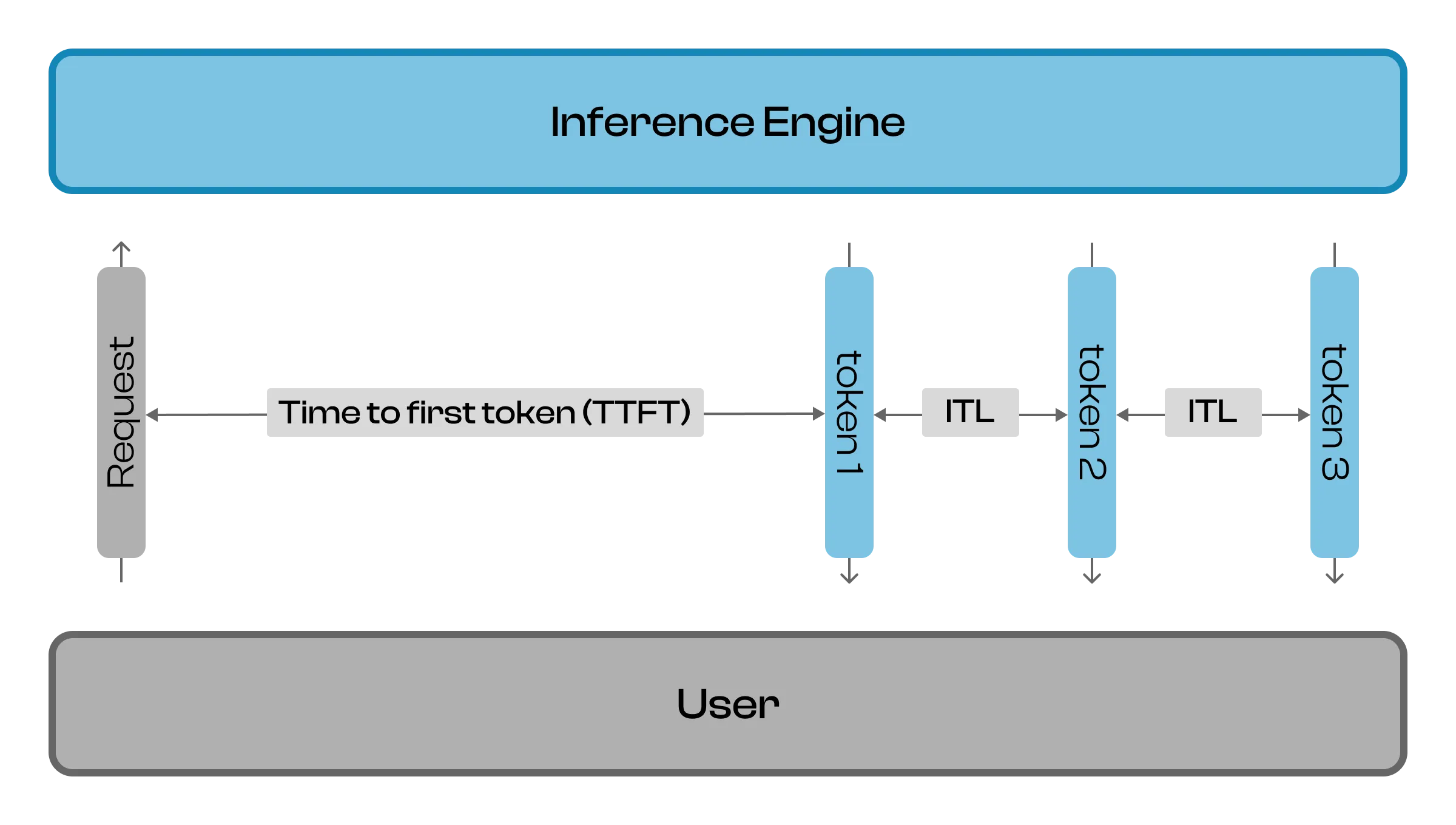
Prefill processes the entire input prompt (all tokens) at once to prepare for generating the first output token. The model computes intermediate states (keys and values) for each transformer layer, storing them in what’s known as the KV cache. Since the full prompt is available, this phase performs highly parallel matrix-matrix operations, efficiently utilizing the GPU’s computational power. This highly parallelized nature allows for full GPU optimization, often making this phase compute-bound. A core metric that measures this phase is the time-to-first-token (TTFT). It’s the time our users wait for the first token to be generated.
Decoding generates output tokens one at a time, using the context built during the prefill phase. The model predicts the next token based on all previously generated tokens, updating the KV cache at each step. Each new token generation is dependent on the tokens that came before, making this an autoregressive process. This phase is a matrix-vector operation, which is less parallelizable for GPUs compared to the prefill phase. The process is limited by the need to access and update the KV cache for every new token, rather than by computation, which makes it memory-bound. For this phase we usually measure inter-token latency (ITL) or time per output token (TPOT).
Let’s look at TTFT first.
As mentioned, TTFT is the time until the user receives the first token, which is our main metric for the prefill phase. This should be small and with a low spread.
MAX is most compact, SGLang quite similar. vLLM has a high spread with the 99-quantile being around 80% larger than MAX.
| TTFT (ms) | Mean | Median | p99 |
|---|---|---|---|
| MAX | 7.15 | 7.33 | 13.10 |
| SGLang | 8.24 (+15%) | 8.04 (+10%) | 17.13 (+31%) |
| vLLM | 7.94 (+11%) | 5.78 (-21%) | 23.61 (+80%) |
MAX wins in most metrics regarding TTFT; only vLLM’s median is smaller, also indicated by the large base in the TTFT plot. So, while vLLM is faster for around half of the prompts, it’s considerably slower for the other half.
vLLM is faster for a lot of requests but then considerably slower for the rest, making it less consistent than MAX and SGLang, which is shown in the large p99 quantile of vLLM.
Next up, ITL and TPOT. ITL and TPOT are two different latency metrics that measure different aspects of token generation.
ITL (Inter-Token Latency) measures the time between consecutive token arrivals during streaming, capturing individual intervals between each token pair and storing them as a list of all individual inter-token intervals - this is useful for measuring the consistency and smoothness of token generation.
TPOT (Time Per Output Token), on the other hand, measures the average time to generate each token excluding the first token, calculated as (total_latency - time_to_first_token) / (number_of_tokens - 1) and providing a single average value per request to measure overall generation speed per token.
If you look at these metrics you will often find that ITL is consistently smaller than TPOT, which might be surprising because they are computed based on the same measurements. The key difference is in what gets averaged:
TPOT averages at the request level first, then averages those request-level averages. So if you have a request that takes 10 seconds to generate 100 tokens, that contributes a TPOT of 100ms per token for that entire request. ITL averages all individual inter-token intervals across all requests directly. So those same 100 tokens contribute 100 individual timing measurements to the ITL calculation.
This creates a significant difference because longer requests tend to have higher per-token times (due to attention computation growing with sequence length, memory pressure, etc.). In the TPOT calculation, a slow 100-token generation gets the same weight as a fast 10-token generation (one data point each). But in the ITL calculation, that slow 100-token generation contributes 100 data points while the fast 10-token generation only contributes 10.
Since ITL gives much more weight to the individual intervals from shorter/faster generations, it ends up being lower than TPOT. An ITL of 91.30ms vs TPOT of 332.97ms suggests that most of the individual token intervals are coming from the faster parts of generation (early tokens, shorter sequences), while the slower parts (later tokens, longer sequences) are getting averaged out in the ITL calculation but properly weighted in the TPOT calculation.
This is why TPOT is generally considered a more reliable metric for overall throughput performance - it treats each request equally regardless of length.
Let’s look at the latency distribution of TPOT:
Strange, this looks heavily skewed. I dug a bit into the code and it looks like if we compute TPOT without the first ITL, the time between first and second token, this highly skewed pattern goes away:
I checked the benchmark script because it seemed like a measurement error at first, but since vLLM is not affected by this and I couldn’t find a mistake in the script, it seems to be internal to the two engines. I am pretty sure we are waiting for the decoding batch size to fill up, but this needs further investigation (and probably a second blog post)1.
Looking again at how we initialized the MAX server via docker, we notice the settings:
docker run --rm --gpus=all --ipc=host -p 8000:8000 --env "HF_TOKEN=${HF_TOKEN}" --env "HF_HUB_ENABLE_HF_TRANSFER=1" -v $HOME/.cache/huggingface:/root/.cache/huggingface modular/max-nvidia-full:latest --model-path Qwen/Qwen3-8B --devices gpu:0 --max-num-steps 10 --max-batch-size 512We just copy-pasted this from the official tutorial on their website.
After reading up on the documentation, it looks like --max-num-steps is actually only used in speculative decoding, a feature that can speed up inference, especially of larger language models, but it’s not activated by default2.
What does it mean for our comparison?
Without digging deeper into the default settings of the engines, it seems that MAX waits longer and prioritizes prefill over decoding. If this is undesirable, you can reduce the max_batch_size or play around with other options like min_batch_size_tg or max_ce_batch_size3.
The TPOT distribution without the first and second token shows that MAX has a very concentrated inter-token latency (which is good!) compared to SGLang and vLLM. Obviously we can’t just ignore the waiting time of the first ITL, so let’s look finally at raw throughput:
Measured by raw throughput, we see that MAX is around 6% faster than SGLang and 16% faster than vLLM, which comes entirely from both faster prefill and decoding phases.
Conclusion
After running 500 prompts through all three inference engines, the results are slightly surprising.
vLLM and SGLang are both regarded as the standard for high-performance LLM inference. MAX, as the newcomer, edges out the competition with a 16% speed advantage over vLLM and around 6% faster throughput than SGLang.
Where MAX wins: Consistent TTFT performance and overall throughput. MAX shows the most predictable behavior with tight latency distributions, especially after the second token. If you value consistency, MAX is a solid choice.
vLLM holds its ground: Despite being slower overall, vLLM has a more mature ecosystem & proven production stability. For roughly half the requests, vLLM actually outperforms the others—it’s just the tail latencies that hurt its averages.
SGLang sits in the middle: Very close to vLLM in throughput, performing similarly to MAX in TTFT but without the throughput advantages.
The big caveat: Our benchmark used default configurations from official tutorials, which means MAX might have been [optimized for batching / configured for different workloads / tuned differently] than the others. The suspicious first-token delays in MAX and SGLang suggest there’s more to investigate around batching strategies and configuration tuning.
Practical recommendations:
MAX is speed competitive and is worth testing with your specific workload. vLLM and SGLang remain safe bets.
But we can’t say how these engines perform with different model sizes, various batch sizes, optimized configurations, and real-world traffic patterns. The batching behavior we observed definitely warrants a deeper dive, probably enough material for that second blog post I mentioned.
This benchmark gives us a good starting point, but as always with infrastructure decisions, test with your own workload before making the switch.
Footnotes
-
We could test this by lowering
--max-batch-size. ↩ -
“The system is optimized when more draft tokens can be evaluated in a single step of the target model. This is controlled by the
--max-num-stepsparameter, which sets the maximum number of tokens the draft model generates before verification by the target model.” Source ↩ -
https://docs.modular.com/max/api/python/pipelines/config/#max.pipelines.lib.config.PipelineConfig.max_num_steps ↩